Autocomplete everywhere that reads your mind
September 26, 2025
To explore uses for our personal AI memory store at Fergana Labs, we built a system-wide contextual autocomplete for MacOS. To hydrate it with context, we built a tool to grab text from input fields via a11y APIs, screen OCR and in some cases a Chrome extension. We named it Codeswitch, and you can try it here!1. For a demo of how it works, see here.
To build this so that it works well on MacOS, we had to make some interesting / unconventional design decisions. In this blog post, I'll walk through these decisions.
Using Accessibility tools to mock grey "ghost" text + replace text
Most of the standard autocomplete operations (suggested text, replacing text for "rephrase feature") are not possible without MacOS a11y APIs, and we leaned on them pretty heavily.
- We generate "ghost text" NSPanel by getting the element and cursor's caret position via AXUIElement Position Attributes
- We also get the bounds of the Panel with
AXUIElementCopyParameterizedAttributeValue, which allows us to render a panel that matches the size of the input field that the cursor is currently in. - For our "rephrase" feature, to insert a rephrase suggestion, we actually manually highlight text and then overwrite the text by copy-pasting, which yields a surprisingly smooth UX.
Our liberal use of a11y APIs unfortunately means that Codeswitch can never live on the app store. But that's fine, we can self-sign and put it on a website.
Hijacking the system clipboard to actually add the suggestion on "tab"
- To ensure that the user doesn't lose the text that they just copied to overwriting, we also implemented a virtual clipboard similar to the Raycast clipboard history extension.
- To handle the case where text is added to the clipboard without CMD-C (for example, a button to click to copy in a browser), we regularly poll for clipboard changes to catch these events and add them to the user's virtual clipboard.
- We handle the "tab" shortcut, as well as intercepting CMD-C and CMD-X events, with Global keyboard shortcut interception via
NSEvent.addGlobalMonitorForEvents(matching:handler:)for a number of shortcuts, including tab.
Reverse engineering Google Docs' canvas-based rendering
It was important to us that the project works in Google Docs. However, Google Docs’ canvas-based rendering made all of our techniques for getting text (accessibility selection to get cursor position for grey text, read text, select text to paste over it) useless. As a workaround, we wrote a chrome extension to help us get this information from the user. Unfortunately, that means users need to install the chrome extension for Codeswitch to work in Docs.
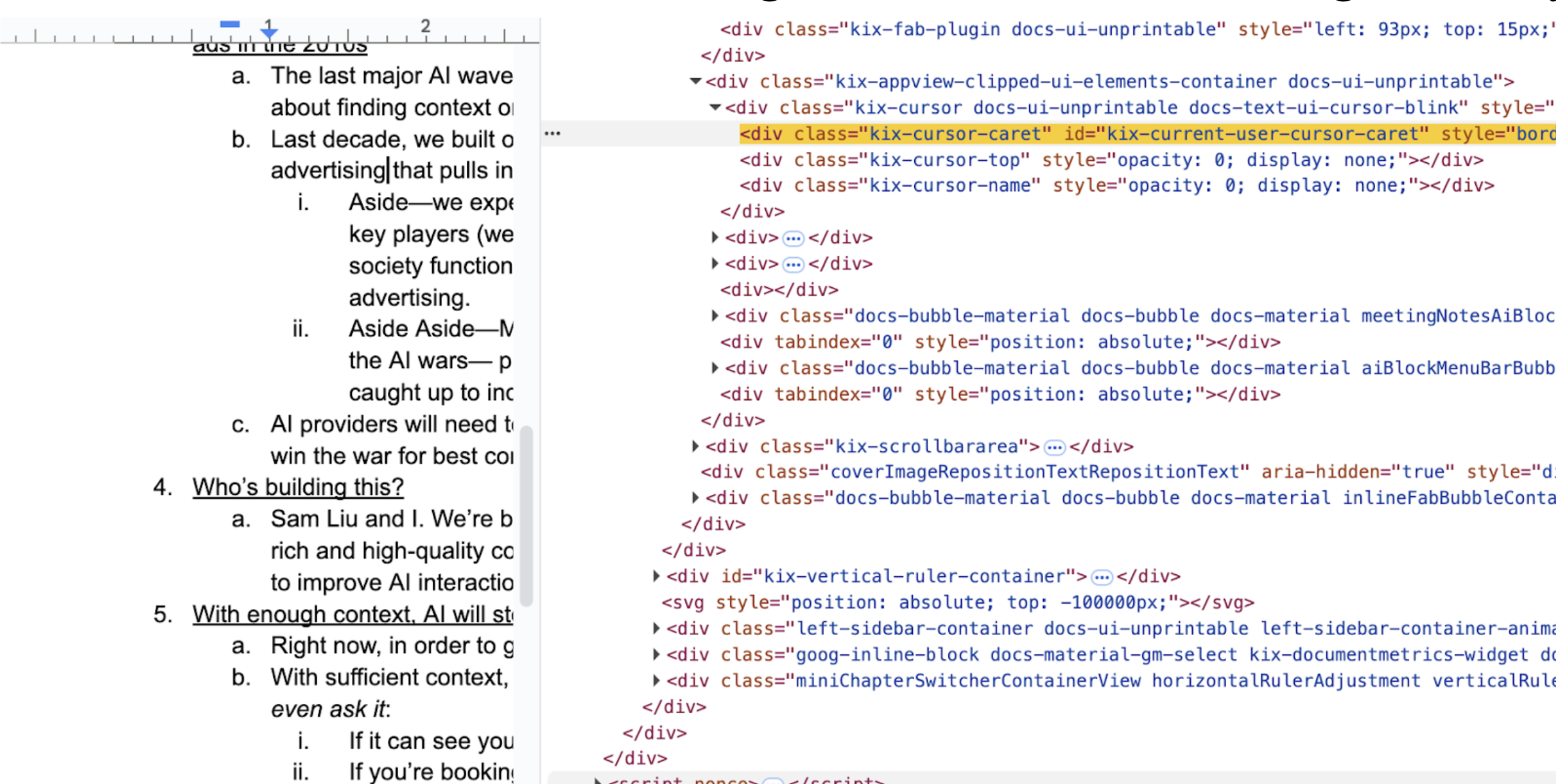
Then we had to figure out what text was selected. Since Google Docs doesn’t actually display any text elements in the browser, we reverse-engineered Google Docs’ API to grab the UI elements that store text within their custom rendering.
- To get cursor, we select for
.kix-cursor-karetin the DOM - To get text, we select
.kix-canvas-tile-selection > svg > rect
We found this discussion of how Google’s Canvas-based rendering works extremely helpful.
Determining selected text in Google Docs
Unfortunately, Google Docs renders each line in the canvas as a monolith, so we still needed to figure out what text was being selected. So, given a cursor position in a line and a set of text in the line, we need to estimate which text was selected. To achieve this, we render actual text invisibly on the page, and then measure at which character the selection must start given its real position.

Screen OCR for context when a11y APIs fail
While accessibility APIs are great when they work, plenty of applications (most notably Chrome) don't properly expose their text content through these channels. We built an OCR system to capture context from these stubborn apps2.
- We used Apple's Vision framework (
VNRecognizeTextRequest) to perform real-time OCR on screen regions around the cursor. The Vision API is surprisingly fast - we could OCR a focused region in ~50ms on an M3 Mac. - We couldn't just OCR the entire screen constantly, due to battery life concerns. To avoid OCRing the same content repeatedly, we implemented a simple cache keyed on window ID + focused element. If the user hadn't switched focus, we'd reuse the previous OCR result.
- Another costly operation was adding our OCR results to the user's AI memory store. To limit waste, we used an edit-distance based heuristic and only sent over a new OCR when text was significantly different, either because the user switched application views or they edited text manually. 3
Learnings
- AI autocomplete with a memory store is *really good* when you're in a mode of work that involves a lot of "copy-pasting" / sending rapidfire emails / slack messages. Here's a scenario where Codeswitch absolutely kills it: your boss asks you to move a meeting, and you need to go and send an email to 5 separate people to get their okay / buy-in.
- Our reverse-engineering approach to Google Docs really only worked because of how fast coding agents can work. With good AI coding agents, we were able to test many promising reverse-engineering approaches in parallel, which allowed us to find a winning strategy in a reasonable amount of time.
- We built this in Swift to take advantage of accessibility APIs. Swift is a nice language with some cool features but XCode is horribly outdated and slow to build in, especially in the AI coding agents era. In hindsight, we should have used Tauri. Thanks to Charlie Holtz for the suggestion!
Shameless plug: If you think this kind of thing is cool, come work with us at Fergana Labs.
- If you're looking for an invite code and don't have one, you may be able to find one if you're clever enough ;) ↩
- The OCR feature is currently disabled by default-- we were concerned with privacy and battery life-- but it can be enabled in app settings if you're brave enough to try it out. ↩
- We also have additional caching in our AI memory store to limit redundancies, but that's for another blog post. ↩
- Related work: check out Tabracadabra, which launched around the same time we built this. When we saw this launch midway through work on this, we concluded that this is an idea that's in the scientific zeitgeist rn.